
Kurz bevor in Deutschland im März 2020 die meisten öffentlichen Veranstaltungen abgesagt oder ins Internet verlegt wurden, fand in Freiburg noch eine nur leicht verkürzte FOSSGIS 2020 statt. Svenja Ruthmann, Studentin in der Fachrichtung Geoinformatik und Vermessung, und Alexander Rolwes, Mitarbeiter und Doktorand am i3mainz, stellten die Resultate aus Ruthmanns Bachelorarbeit vor.
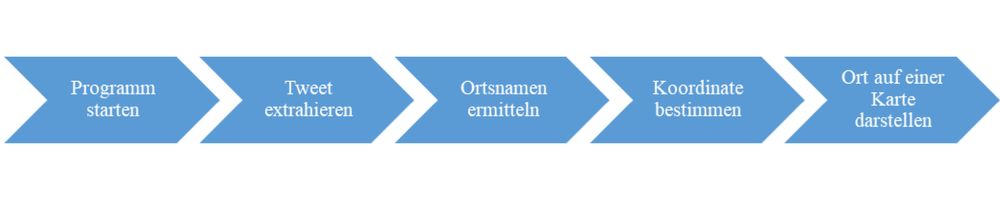
Der von Svenja Ruthmann im Rahmen ihrer Bachelor-Arbeit entwickelte algorithmische Ablauf, Grafik: Hochschule Mainz, cc-by 4.0
Die Studentin war im Rahmen des Projektes BAM - Big-Data-Analytics in Environmental and Structural Monitoring des i3mainz der Frage nachgegangen, ob es möglich ist, Tweets geografisch zu verorten und darzustellen. Die Schwierigkeit dabei: Aus der Twitter-API gehen Koordinaten und Standort des Tweets nur hervor, wenn die Standortfreigabe aktiviert ist. Wird der Tweet später, etwa im Büro mit einem stationären PC verfasst, ist die Standortangabe i.d.R. nicht aktiv und darüber hinaus passt sie nicht zu dem im Tweet beschriebenen Geschehen. Außerdem: Verlinkungen, Bilder oder Videos und verkürzte Sätze erschweren die Textanalyse. Die Zielsetzung des Projekts war, die Koordinaten des Geschehens aus einem Tweet zu ermitteln und auf einer Karte darzustellen.
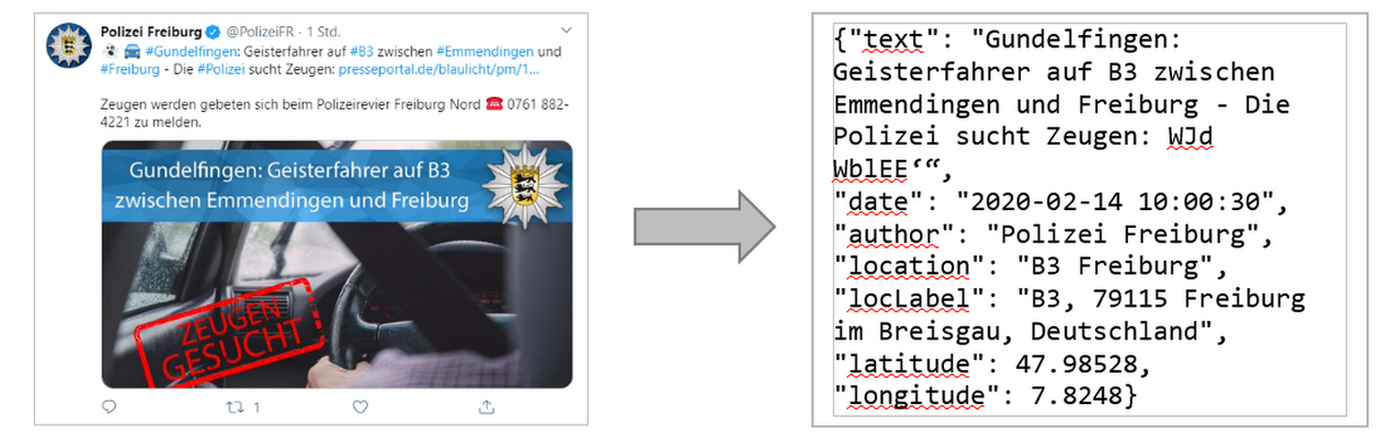
Der aus dem Ablauf resultierende Prototyp generiert die Ergebnisse im JSON-Format. Grafik: Hochschule Mainz, cc-by 4.0
In die Untersuchung flossen exemplarisch in Deutsch verfasste Tweets von Polizeibehörden ein, zur Auswertung wurden ausschließlich bereits existierende Werkzeuge verwendet. Bestehende Anwendungen arbeiten jedoch nur mit englischen Tweets, z.B. Mordecai oder der Location Name Extractor. Svenja Ruthmann entwickelte daher den folgenden algorithmischen Ablauf: Der Text aus der Twitter-API wird weiterverarbeitet, indem Umlaute ersetzt, Links und Sonderzeichen, wie Hashtags oder Emoticons, entfernt werden. Für die Ermittlung der Ortsnamen unterteilt der Natural Language Prozessor spaCy die Tweets in Entitäten, wie Nomen oder Verben. Um zu überprüfen, ob ein Tweet die Abkürzung eines KFZ-Kennzeichens enthält, werden alle Eigennamen mit einer selbst generierten Datenbank abgeglichen und gegebenenfalls im Tweet durch den vollständigen Namen ersetzt. Anschließend wird der Geocoder von HERE eingesetzt, um die Koordinaten zu generieren.
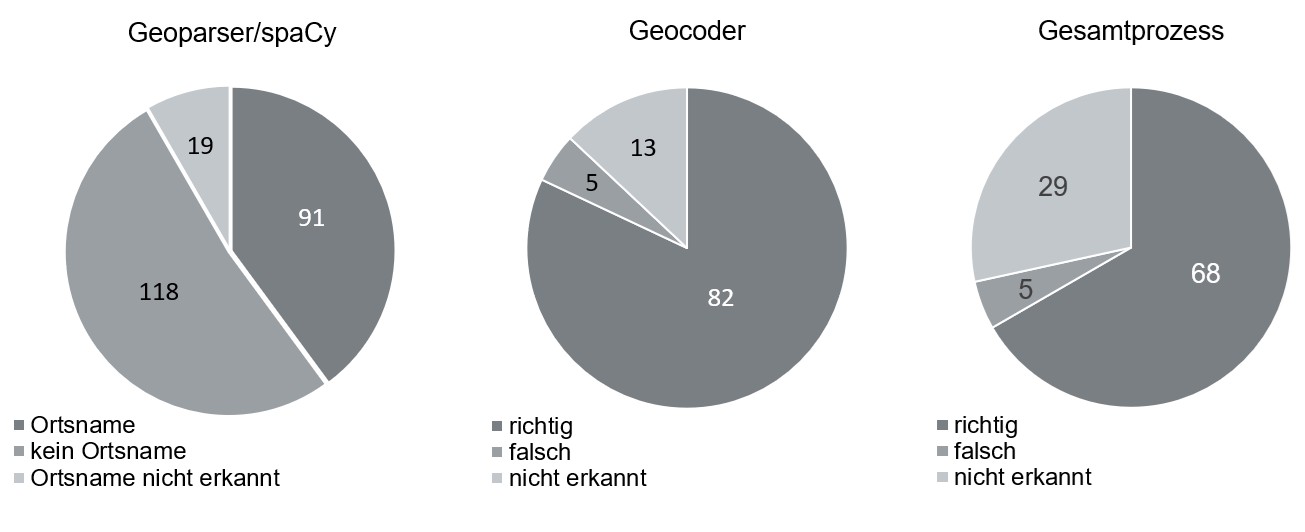
Die Untersuchung betrachtete zunächst den Natural Language Prozessor sowie den Geocoder getrennt voneinander, um anschließend das Ergebnis nach dem Ablauf des gesamten Programms zu prüfen, Grafik: Hochschule Mainz, cc-by 4.0
Der aus dem Ablauf resultierende Prototyp generiert die Ergebnisse im JSON-Format, welches ideal weiterverarbeitet werden kann, z.B. zur Darstellung auf einer HTML Seite. Zur Evaluation des Verfahrens wurden 100 Tweets analysiert. Das Programm ermittelte 68 Ortsnamen korrekt, fünf falsch und 29 ohne Raumbezug. Die verfügbaren Bibliotheken und Dienste liefern offensichtlich eine solide Basis für die Verortung von Tweets, auch wenn weitere Entwicklung notwendig ist, um die positive Erkennungsrate zu erhöhen. Fehlzuordnungen werden vor allem durch mehrfach existierende Ortsnamen (Frankfurt am Main vs. Frankfurt an der Oder) erzeugt. Der entwickelte Prozess lässt sich zunächst optimieren, indem spaCy mit einem signifikanten Datensatz von Tweets und deutschen Ortsnamen trainiert wird. Die Optimierung ist Gegenstand von zukünftigen Vorhaben.



